SWE-benchの精度をまとめてみた(25年2月時点)
生成AI界隈は動きが激しく、各社から新しいモデルがでてキャッチアップしていくのが大変です。そのため25年2月時点の主要な生成AIのSWE-benchの結果をまとめてみました。
SWE-benchとは
SWE-benchは、GitHubから収集した実際のソフトウェアのIssueに対する大規模言語モデル(LLM)の評価のためのベンチマークです。
データセットは、有名なPythonの12のリポジトリからIssueとPRのペアを2,294件集めているようです(引用元)。そして、LLMにコードベースとIssueが与えられ、LLMはIssueを解決するパッチを作成することが求められます。
https://www.swebench.com/ では、Leaderboardとして正答率のランキングを見ることができます。
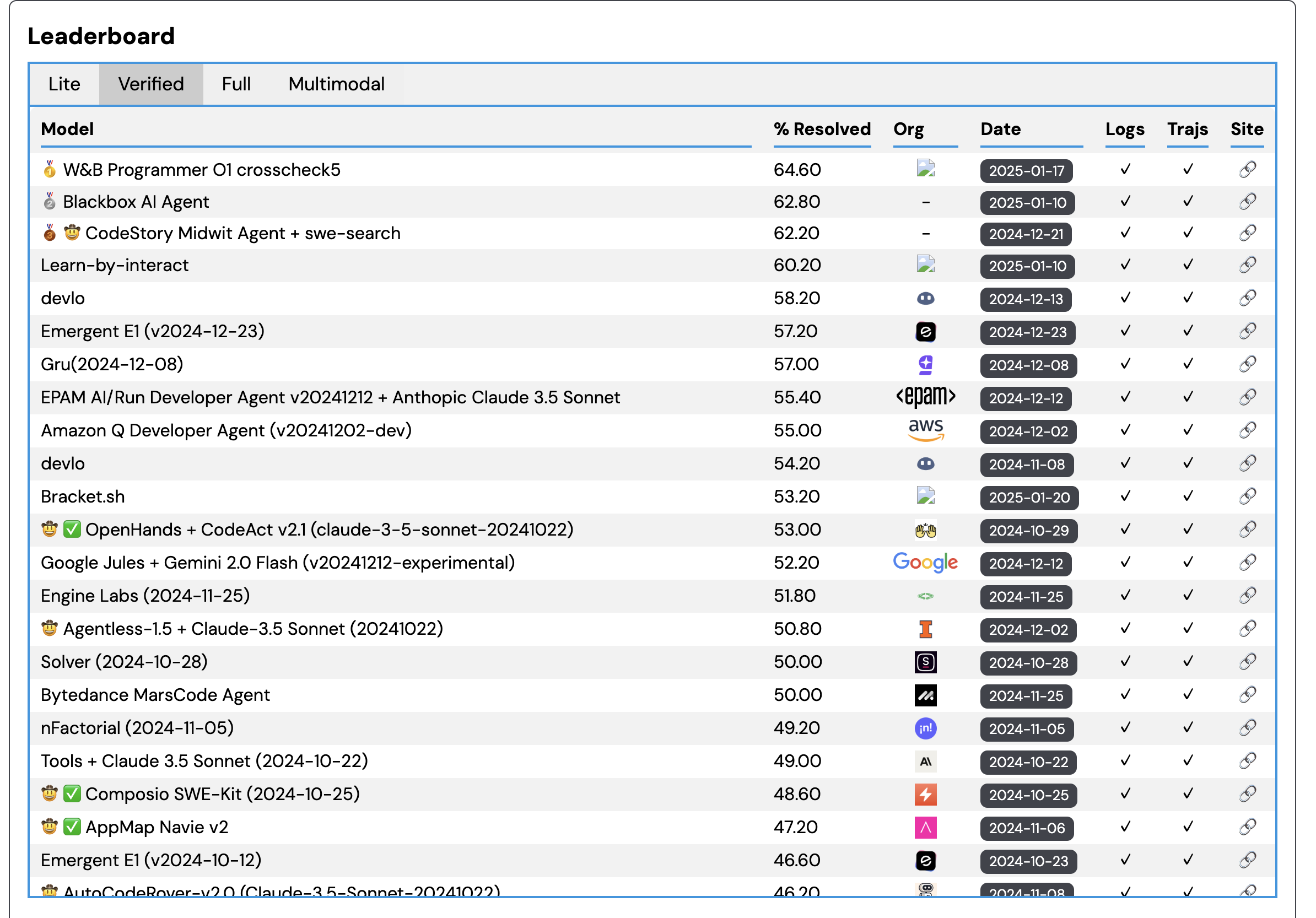
25年2月時点のSWE-bench Verified の精度
主要モデルで比較すると次のようになっています。現時点で公開中のモデルでは50%前後と均衡しています。
o3だけ群をぬいていますが、今は非公開なので残念ながら利用はできないです。数ヶ月以内にGPT-5に含まれるという話もあるので期待しています。
ちなみに、企業でのコーディングでは Claudeが精度が良いという話があったりします。
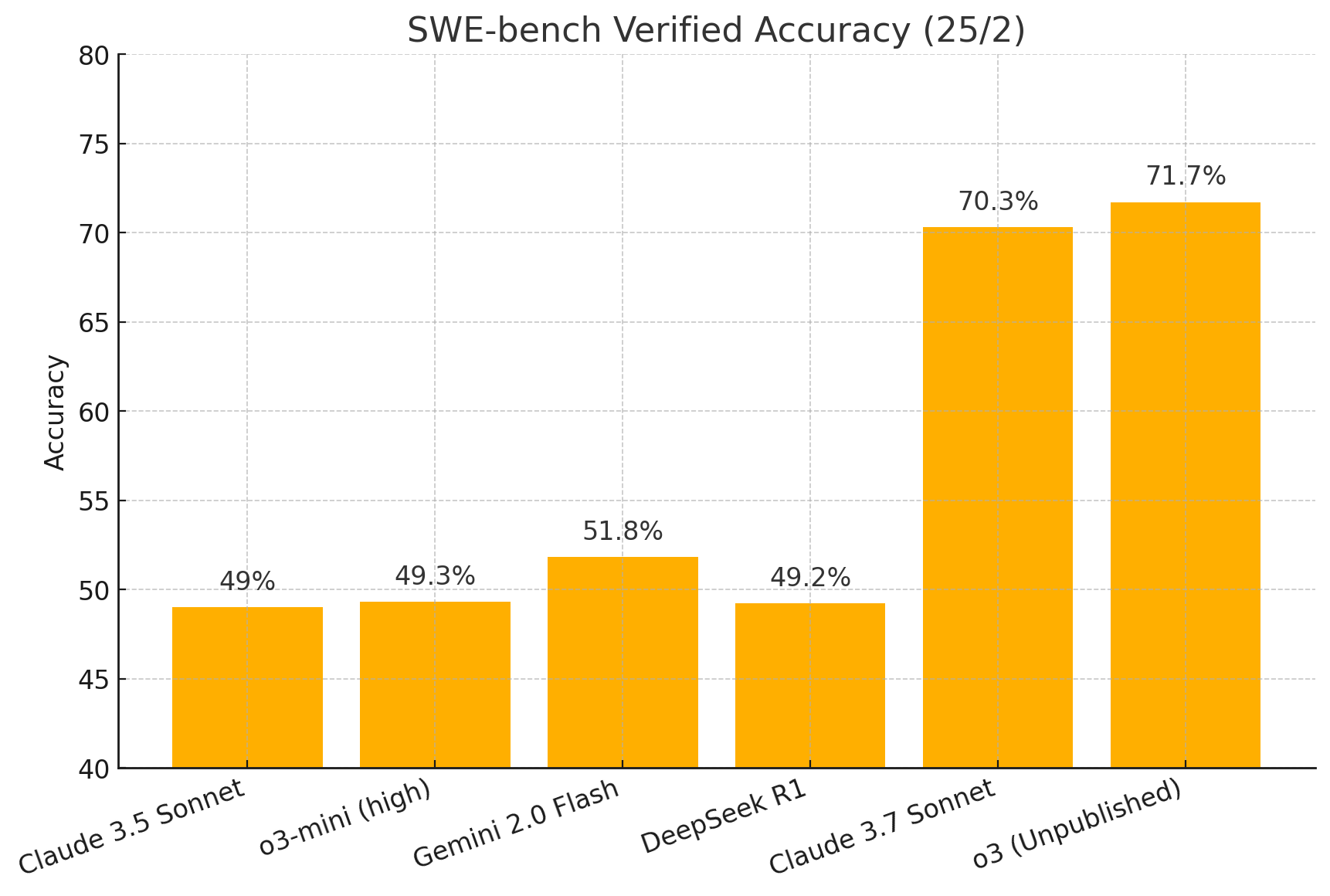
モデル名 | 精度 | 引用元 |
|---|---|---|
Claude 3.5 Sonnet | 49% | Raising the bar on SWE-bench Verified with Claude 3.5 Sonnet \\ Anthropic |
o3-mini (high) | 49.3% | |
Gemini 2.0 Flash | 51.8% | |
DeepSeek R1 | 49.2% | |
Claude 3.7 Sonnet | 70.3% | |
o3 | 71.7% |