LlamaIndexを使ってChatGPTにGitHubリポジトリについて答えてもらう
LlamaIndex を使って、GitHubのリポジトリの内容について回答できるようにしました。
23年4月時点ではChatGTP-4の最新の学習データは2021年9月 1になっており、それ以降の情報は聞いても教えてもらえません。
例えば、次のようにGitHubの llama_indexリポジトリについて聞いてみた結果「詳しく説明できません」と回答されてしまいます。
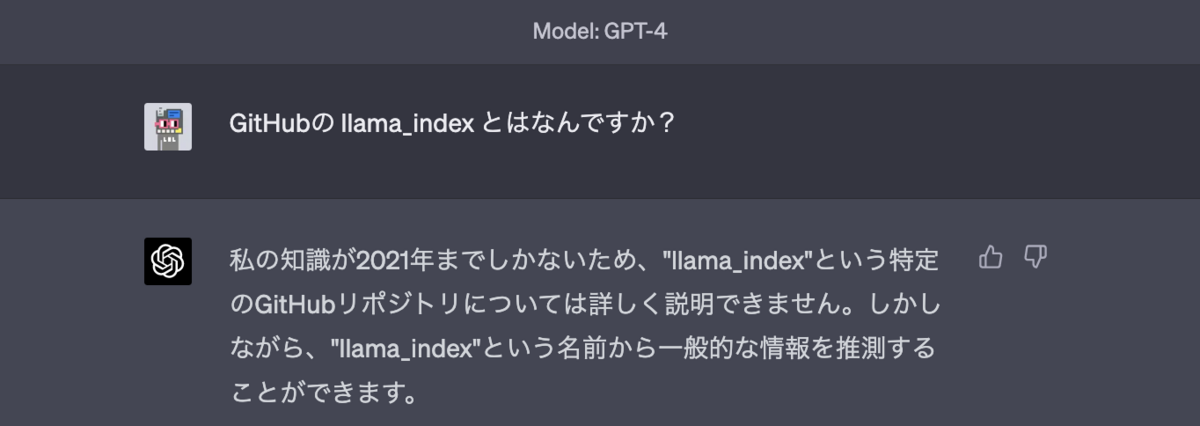
※24年12月時点では主要なLLMではWeb検索機能も使えるので学習データ問題も解消されています。
そこで、今回は LlamaIndex を使って、GitHubのリポジトリの内容について回答できるようにしました。
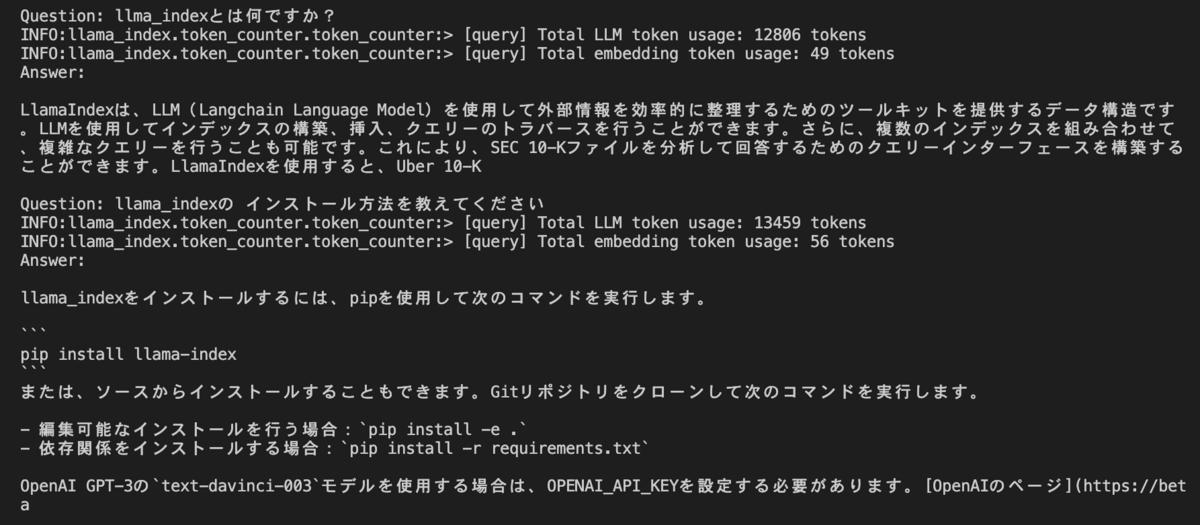
結果としては、llama_indexについて回答してくれるようになっています。
1. LlamaIndex とは
LlamaIndex は、外部データと大規模言語モデル(LLM) を結合するシンプルで利用しやすいツールキットです。LlamaIndex を利用することで、独自のデータにもとづいてChatGPTなどのLLMに回答をさせることができます。
LlamaIndex は、次のようなツールを提供しています。
- 既存のデータソースとデータ形式へのデータコネクタ
- Llama Hub に実装が公開されており、slack, twitter, pdf, google docsなどさまざまなデータソースからデータを取得できます
- LLMを利用したインデックス構築
- ChatGPTなどのLLMを使用して、取得したデータのインデックスを作成できます。
- インデックスを活用したクエリ実行
- 作成したインデックスを利用したプロンプトを生成し、LLMにクエリを投げることができます。
2. LlamaIndex の仕組み
LlamaIndexは次の流れで、LLMに対して独自のデータにもとづいた回答をさせることを実現しています。
- インデックス作成
- クエリ実行
2.1. インデックス作成
インデックス作成では、データソースからデータを取得し、LLMを利用してインデックスの作成をしています。
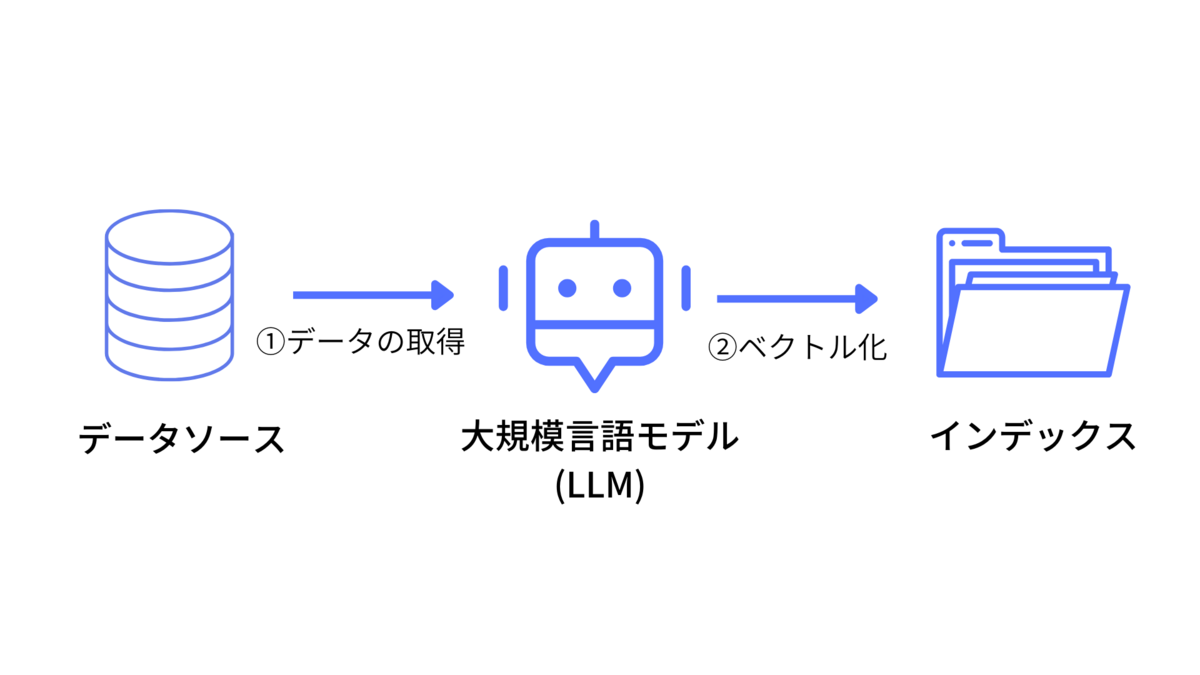
まず、データソースからデータを取得します。LlamaIndexでは Llama Hub というさまざまなデータソースからデータを取得するコネクタが用意されています。これを使うことで、簡単にデータを取得できます。コネクタには、notion, jira, twitter, slackなどのWebサービスから、pdf, docx, pptx, epubなどのファイルなど幅広いコネクタが存在しています。
つぎに、データをチャンクという単位で分割して、LLMでベクトル化することでインデックスを作成します。たぶんですが、LLMのEmbeddin APIを利用してベクトル化しています。
2.2. クエリ実行
クエリ実行では、質問文に類似するコンテンツをインデックスから探し、そのコンテンツ内容を含めたプロンプトを生成し、LLMに問い合わせることで独自のデータにもとづいた回答をさせています。
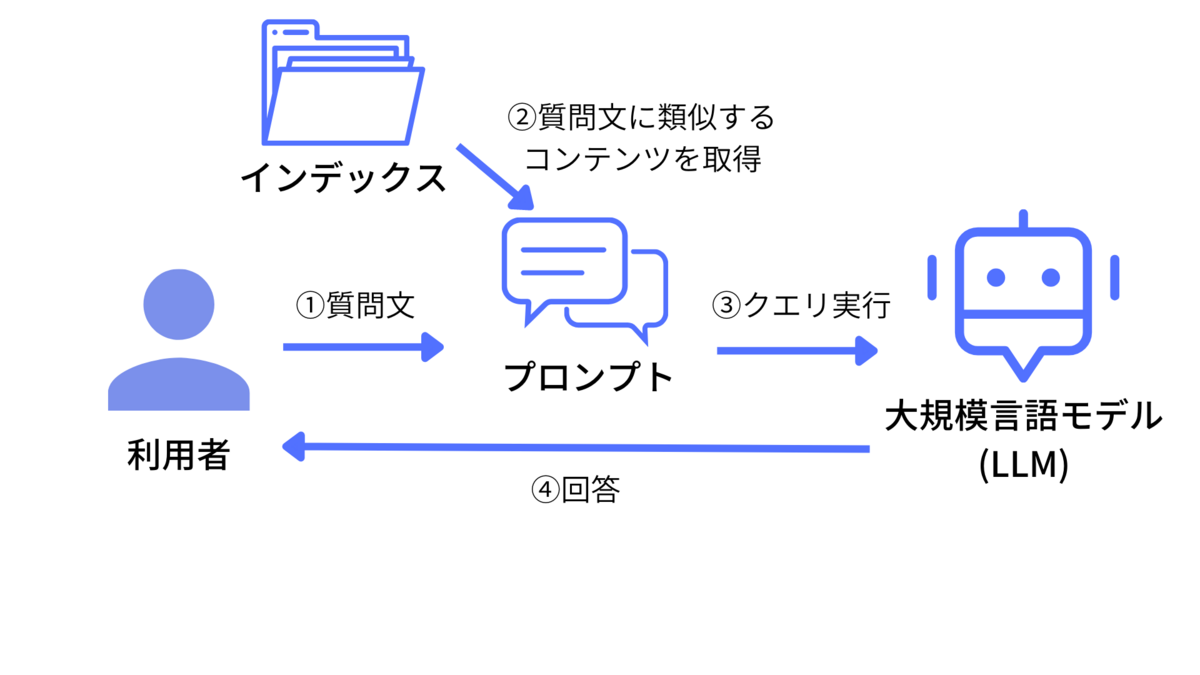
まず、利用者の質問文を受けつけます。つぎに、質問文に類似するコンテンツを取得し、それをプロンプトに含めます。そして、LLMにプロンプトを送信することでコンテンツに基づいた内容を回答させています。
生成されるプロンプトのイメージとしては次のようになります。
以下の内容にそって質問文に回答してください
[内容]
{質問文に類似するコンテンツの内容}
[質問文]
{ユーザの入力文}
[回答]3. LlamaIndexを使って特定のGitHubリポジトリについて答えさせる
では、LlamaIndexを使って、GtHubリポジトリのインデックスを作成し、リポジトリの内容について回答できるようにしてみます。
ソースコードは https://github.com/nipe0324/llamaindex-github-repo-demo に公開していますので、詳細が気になる方はコードを読んでみてください。
3.1 インデックスの作成
まず、GitHubリポジトリからデータを取得し、インデックスを追加します。
以下のようにコマンドを実行することでインデックスを作成できるようにしました。
$ python make_index.py --owner jerryjliu --repo llama_indexソースコードの中身としては、GitHubリポジトリからのデータ取得では、Llama HubにGithub Repository Loader があるのでこちらを利用します。コネクタの利用にあたり、GitHubのパーソナルトークンが必要なので作成します。 また、インデックス作成時のLLMには、ChatGPTを使うので OpenAIのAPI Tokenも作成します。
import argparse
import os
import sys
from langchain.llms import OpenAI
from llama_index import download_loader, GPTSimpleVectorIndex, LLMPredictor, ServiceContext
download_loader("GithubRepositoryReader")
from llama_index.readers.llamahub_modules.github_repo import GithubClient, GithubRepositoryReader
if os.environ.get("OPEN_API_KEY") == "":
print("'OPEN_API_KEY' not set", file=sys.stderr)
sys.exit(1)
if os.environ.get("GITHUB_TOKEN") == "":
print("'GITHUB_TOKEN' not set", file=sys.stderr)
sys.exit(1)
def make_index_from_github_repo(owner, repo, branch, filter_directories, filter_file_extensions):
print("Making index for repo: {}/{} with {} branch".format(owner, repo, branch))
print("Filtering directories: {}".format(filter_directories))
print("Filtering file extensions: {}".format(filter_file_extensions))
# ref: https://llamahub.ai/l/github_repo
github_client = GithubClient(os.getenv("GITHUB_TOKEN"))
loader = GithubRepositoryReader(
github_client,
owner = owner,
repo = repo,
filter_directories = (filter_directories, GithubRepositoryReader.FilterType.INCLUDE),
filter_file_extensions = (filter_file_extensions, GithubRepositoryReader.FilterType.INCLUDE),
verbose = True,
concurrent_requests = 10,
)
docs = loader.load_data(branch="main")
index = GPTSimpleVectorIndex.from_documents(
docs,
service_context=get_service_context(),
)
index.save_to_disk("index.json")
print("Index saved to index.json")
def get_service_context():
llm_predictor = LLMPredictor(llm=OpenAI(temperature=0, model_name="text-davinci-003"))
return ServiceContext.from_defaults(llm_predictor=llm_predictor)
def main(args):
make_index_from_github_repo(
args.owner,
args.repo,
args.branch,
args.filter_directories,
args.filter_file_extensions,
)
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="Make index file for a GitHub repo")
parser.add_argument("--owner", help="GitHub repo owner", required=True)
parser.add_argument("--repo", help="GitHub repo name", required=True)
parser.add_argument("--branch", help="GitHub repo branch", default="main")
parser.add_argument("--filter-directories", help="Directories to filter", default=["README.md", "docs"])
parser.add_argument("--filter-file-extensions", help="File extensions to filter", default=[".md"])
args = parser.parse_args()
main(args)
3.2 インデックスを利用したクエリの実行
つぎに、インデックスを利用したクエリの実行をしてみます。
以下のようにコマンドを実行することでチャット形式で質問と回答のやりとりができるようにしています。
$ python chat.py
Loading index...
Question: What is llama_index?
Answer: LlamaIndex is a project that provides a central interface ...
Question: how to install llama-index?
Answer: To install LlamaIndex, run the following command:
`pip install llama-index`
...ソースコードの中身としては、保存したインデックスをロードし、index.queryでクエリを実行しています。
import argparse
import os
import sys
from langchain.llms import OpenAI
from llama_index import GPTSimpleVectorIndex, LLMPredictor, ServiceContext
PROMPT_TEMPLATE = """
Answer the question below based on the book as if you were the author.
Question: {question}
Answer to the question in the same language as the question.
"""
if os.environ.get("OPEN_API_KEY") == "":
print("'OPEN_API_KEY' not set", file=sys.stderr)
sys.exit(1)
def chat_for_github_repo():
index = load_index()
print("Question: ", end="", flush=True)
try:
while question := next(sys.stdin).strip():
prompt = PROMPT_TEMPLATE.format(question=question)
output = index.query(prompt, similarity_top_k=5)
print("Answer: ", end="")
print(output)
print("")
print("Question: ", end="", flush=True)
except KeyboardInterrupt:
print("Bye!")
pass
def load_index():
print("Loading index...\n")
return GPTSimpleVectorIndex.load_from_disk(
"index.json",
service_context=get_service_context(),
)
def get_service_context():
llm_predictor = LLMPredictor(llm=OpenAI(temperature=0, model_name="text-davinci-003"))
return ServiceContext.from_defaults(llm_predictor=llm_predictor)
def main():
chat_for_github_repo()
if __name__ == "__main__":
main()
今回は、LlamaIndexを使ってChatGPTにGitHubリポジトリについて答えてもらうことを試しました。LlamaIndexの公式ドキュメントをみるとインデックスやプロンプト生成などでチューニングの余地がいろいろあることがわかります。
ぜひ、おもしろそうと思ったら自分でも試してみてください!