Code Interpreterで タイタニックの データ分析をしてみた
ChatGPTのCode Interpreter を使って、kaggleのタイタニックのデータ分析をしてみました。 データ分析からモデルで予測まで一通り実施できました。また、予測結果をkaggleに提出するとScoreは0.77511でまずまずの結果でした。
Code Interpreterとは
Code Interpreterを使うことで、チャット上でPythonコードを自動的に書いて実行できるChatGPTの公式プラグインです。ファイルのアップロードやダウンロードもサポートしています。そのため、データ分析、画像変換、Pythonコードの編集などに活用できます。
23年8月現時点では、Chat GPT Plusユーザー(月額20ドル)が利用できBeta機能としての提供です。
kaggleのタイタニックの問題とは
Titanicは、Kaggleの使い方に慣れるための最初のチャレンジとして推奨されている機械学習の問題です。
このコンペティションの目的は、タイタニック号の難破からの生存者を予測するモデルを機械学習を使用して作成することです。
どのような乗客の特性が生存率に影響を与えたかを分析して機械学習モデルを作ってテストデータに対して予測結果を提出します。
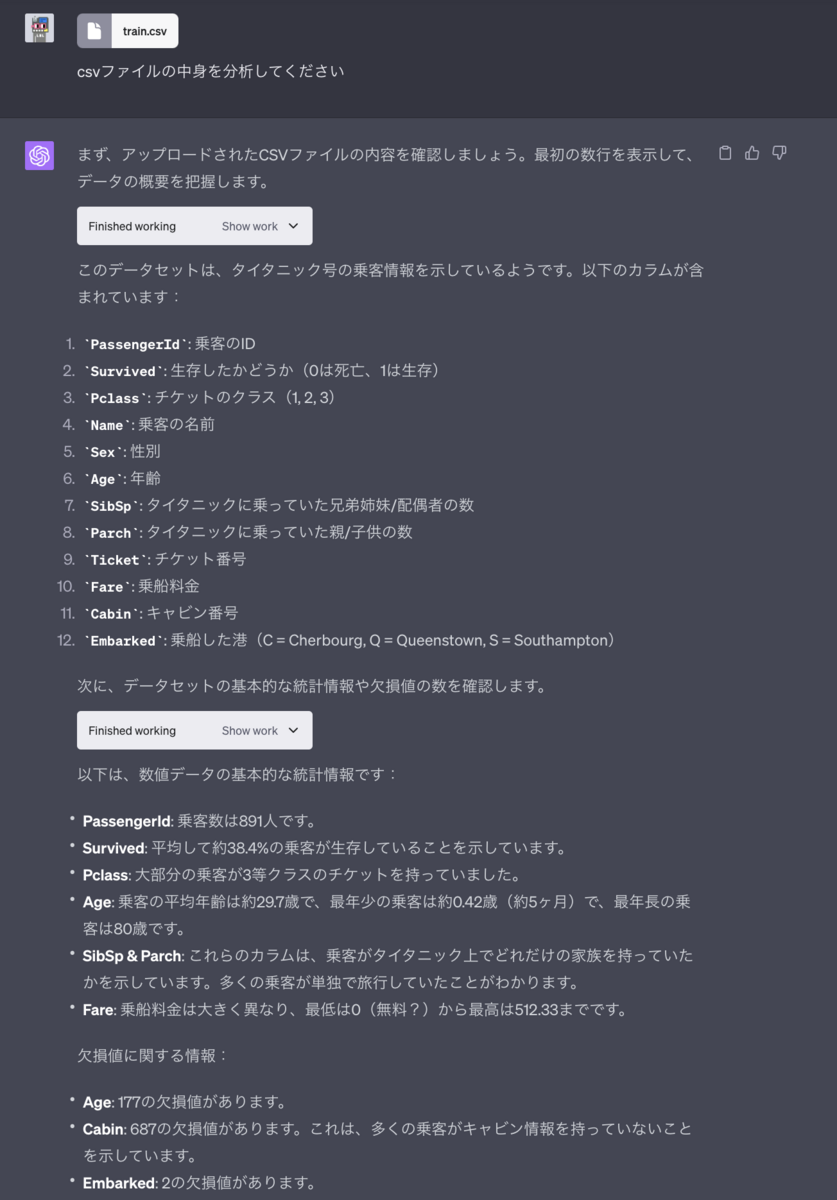
kaggleのタイタニックのデータ分析
kaggleからtrain.csvをダウンロードして、Code Interpreterに雑に分析してもらいます。
データセットの内容、統計情報、欠損値について教えてくれます。pythonのコードとしては、pandasを利用して統計情報を表示しているようです。
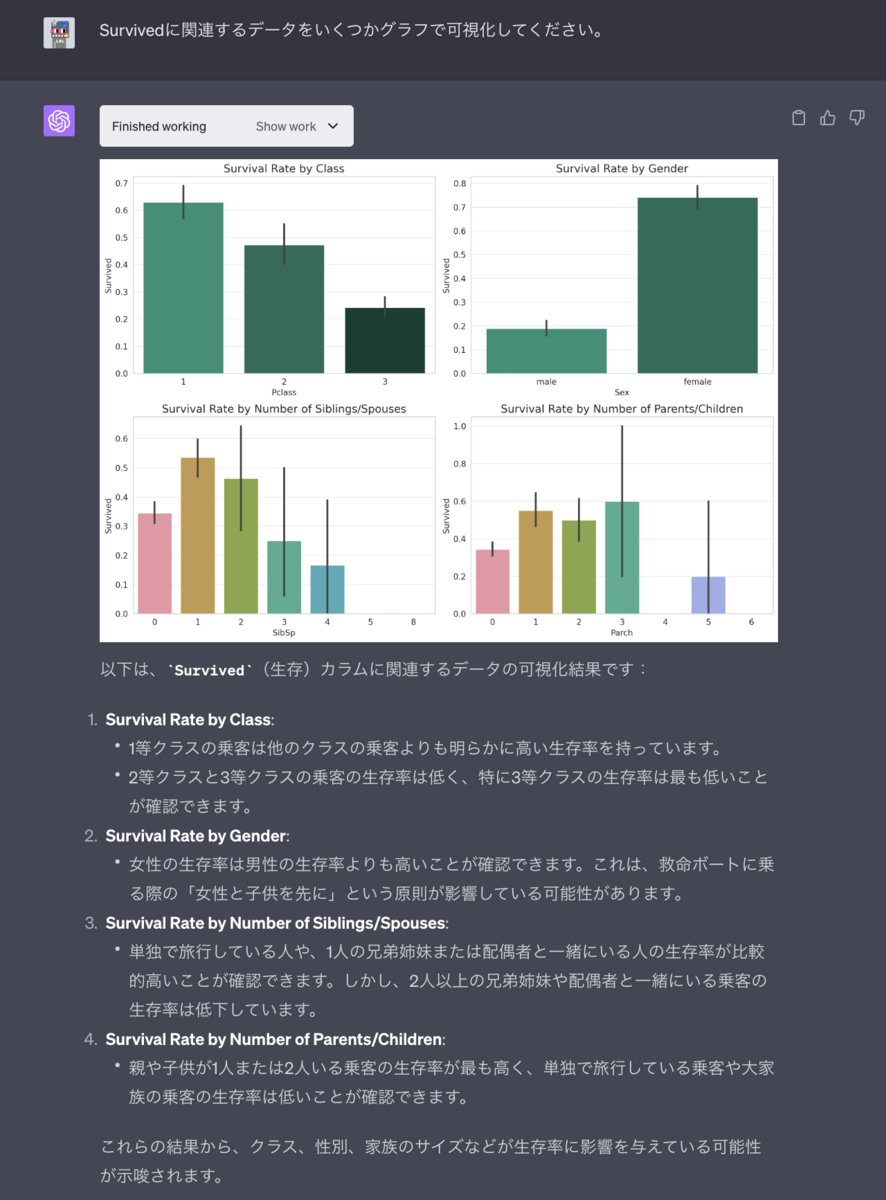
kaggleのタイタニックの可視化
次に、csvのデータをグラフで可視化してみます。タイタニックではSurvived(生存したかどうか)を予測する問題なので、Survivedに関連するグラフを表示してみます。
客室のクラス、性別、兄弟姉妹の数、親や子供の数などの違いによりどれだけSurvivedが変わるかをグラフで表示しつつ、グラフの結果について結果もわかりやすくまとめてくれています。
kaggleのタイタニックの予測モデルの作成
ここからが本題で、タイタニックの予想モデルを作成してもらいます。モデルの生成と評価をステップバイステップで実行してくれます。

データの前処理、3つのモデルのトレーニングと精度の評価、一番精度が高かった勾配ブースティングで検証の実施と機械学習のステップを自動的に実施してくれています。(すごい!!)
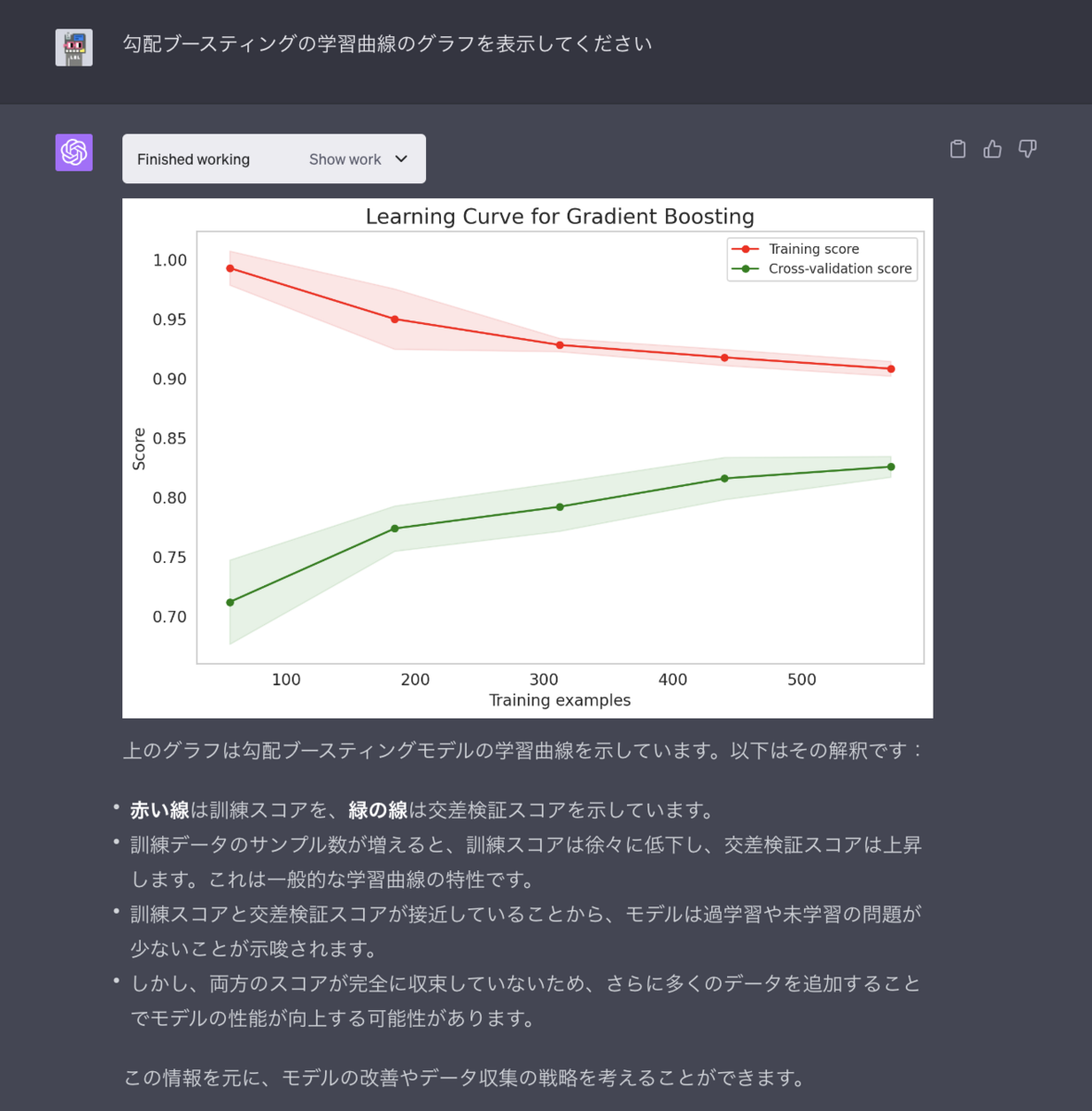
ここで、学習過程をみるために学習曲線を表示してもらいます。学習曲線のグラフ表示だけではなく、グラフの説明もしておりとてもわかりやすいです。
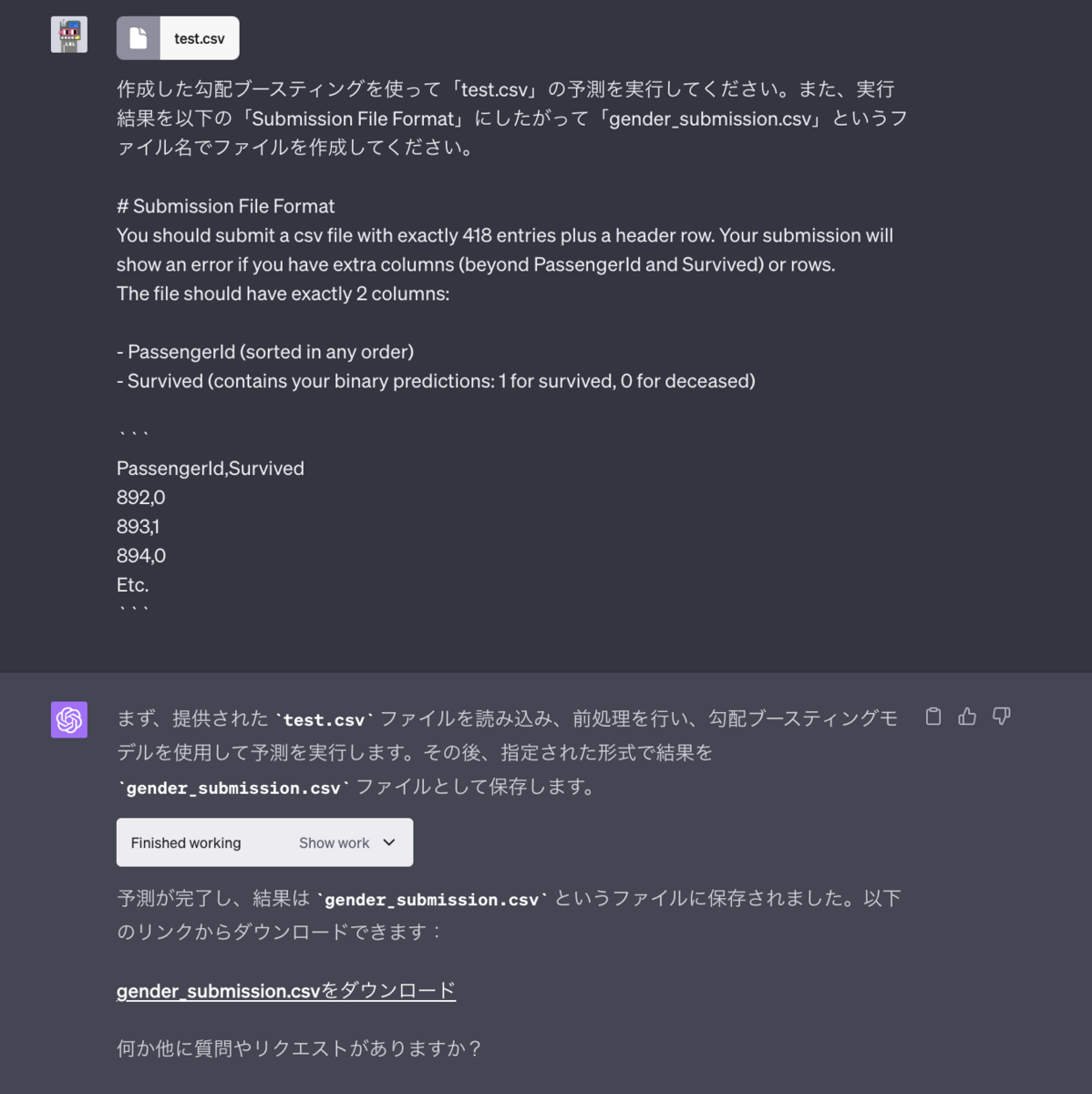
kaggleのタイタニックの予測の実施
では、最後にタイタニックのtest.csvのデータを使って予測を実施します。ついでにkaggleの提出用ファイルを作成してもらっています。
この「gender_submission.csv」をダウンロードして、kaggleに提出するとScoreは0.77511でまずまずの結果でした。